Table of Contents
Reducing Change Failure Rate Through Smaller Deployments
Learn practical strategies for reducing Change Failure Rate by improving deployment practices, breaking work into smaller changes, and aligning coding workflows with DORA measurement principles.

Reducing Change Failure Rate starts long before deployment. One of the strongest predictors of deployment risk is how long and how much code is written before it is released.
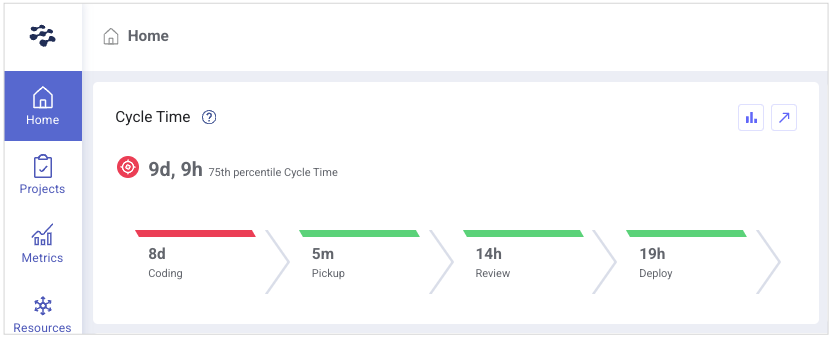
On average, teams maintain a coding time of 3–4 days, while elite teams consistently achieve a coding time of approximately 1 day. Shorter coding cycles usually translate into smaller deployments, which are easier to review, test, and roll back if needed.
Summary
- Smaller deployments reduce the likelihood of failed changes.
- Long coding time often leads to large pull requests and risky releases.
- Elite teams maintain short coding cycles to limit deployment impact.
- LinearB helps identify high-risk coding patterns before they reach production.
Identifying high coding time
Team level
- In the Home dashboard, set your view to All Teams. When coding time is high, the Cycle Time → Coding metric appears in red.
Branch level
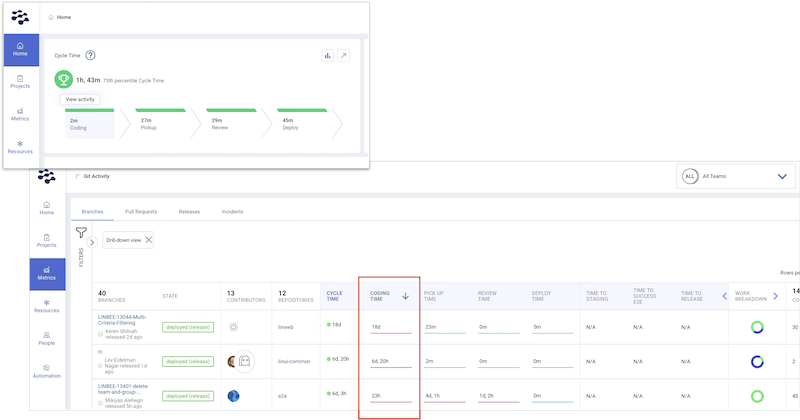
- In the Home dashboard, keep the view set to All Teams, then click the Cycle Time → Coding metric to identify branches with extended coding duration.
Why high coding time increases change failure risk
-
Undivided tasks
Large pull requests often indicate work that was not broken into manageable units. Larger changes increase the chance of defects and make failures harder to isolate. -
Unclear project requirements
Ambiguous requirements can inflate the scope of a change, increasing uncertainty and deployment risk. -
Complex or hard-to-read code
Codebases that require frequent rework or refactoring are more error-prone, especially when changes are deployed in bulk. -
Excessive work in progress (WIP)
Multiple concurrent tasks lead to context switching and delayed feedback, resulting in larger, riskier deployments. Use the Pulse view to balance workloads and limit simultaneous work.
Strategies to reduce change failure rate
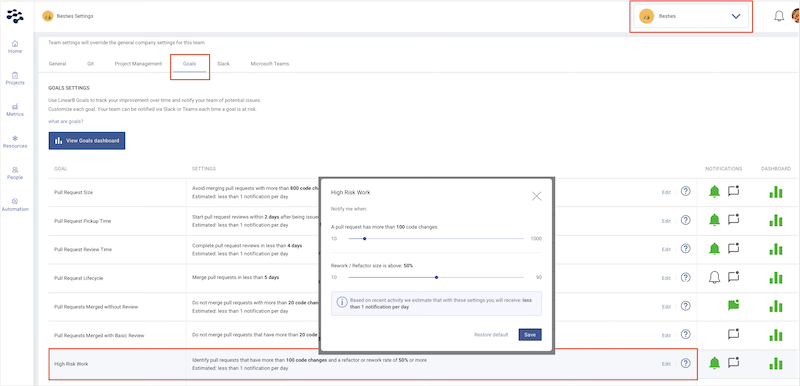
Set up Slack alerts for high-risk work
Configure Slack alerts to notify your team in real time when pull requests become large or heavily revised. Early intervention helps teams split changes before they reach deployment.
- In the LinearB side menu, click Settings.
- From the Teams dropdown, select the team you want to alert.
- Navigate to the Goals tab.
- Edit the High Risk Work goal.
- Set the alert threshold for the maximum number of code changes per pull request (for example, 50 or 100 changes).
- Define the Rework / Refactor threshold (for example, above 50%).
- Click Save.
Once configured, alerts are sent directly to the team’s Slack channel. Developers can open the pull request from Slack, reducing review delays and limiting change size before deployment.
Build a metrics dashboard
Use LinearB’s Metrics tab to build a custom metrics dashboard tracking Coding Time, PR Size, and Active Branches. Monitoring these trends helps identify deployment risk before changes reach production.
Monitor large PRs and high work in progress
Regularly review large pull requests and team workload in the Pulse view. Keeping changes small and work balanced reduces deployment risk and lowers change failure rate.
By consistently deploying smaller, focused changes, teams can significantly reduce change failure rate while improving delivery stability.
How did we do?
Mean Time to Restore (MTTR): Definition and Calculation
Reliability & DORA Metrics