Table of Contents
Release Notes - November 2025
Improved accuracy for AI Code Reviews. Upgrade to Claude Sonnet 4.5 The latest Claude AI model, Sonnet 4.5, now powers the LinearB AI Code Review. With this upgrade, our internal testbench score impr…
Improved accuracy for AI Code Reviews
Upgrade to Claude Sonnet 4.5
The latest Claude AI model, Sonnet 4.5, now powers the LinearB AI Code Review. With this upgrade, our internal testbench score improved by another 5% in accuracy, boosting review quality to provide you with more precise detection of issues and better context.
Language-specific review logic
AI Code Review now includes language-specific logic to improve accuracy and deliver more relevant, actionable feedback.
Language | New rules |
SQL |
|
BigQuery (SQL variant) |
|
TypeScript |
|
C# |
|
SCSS |
|
HCL |
|
YAML |
|
Clearer visuals for code suggestions in PR reviews
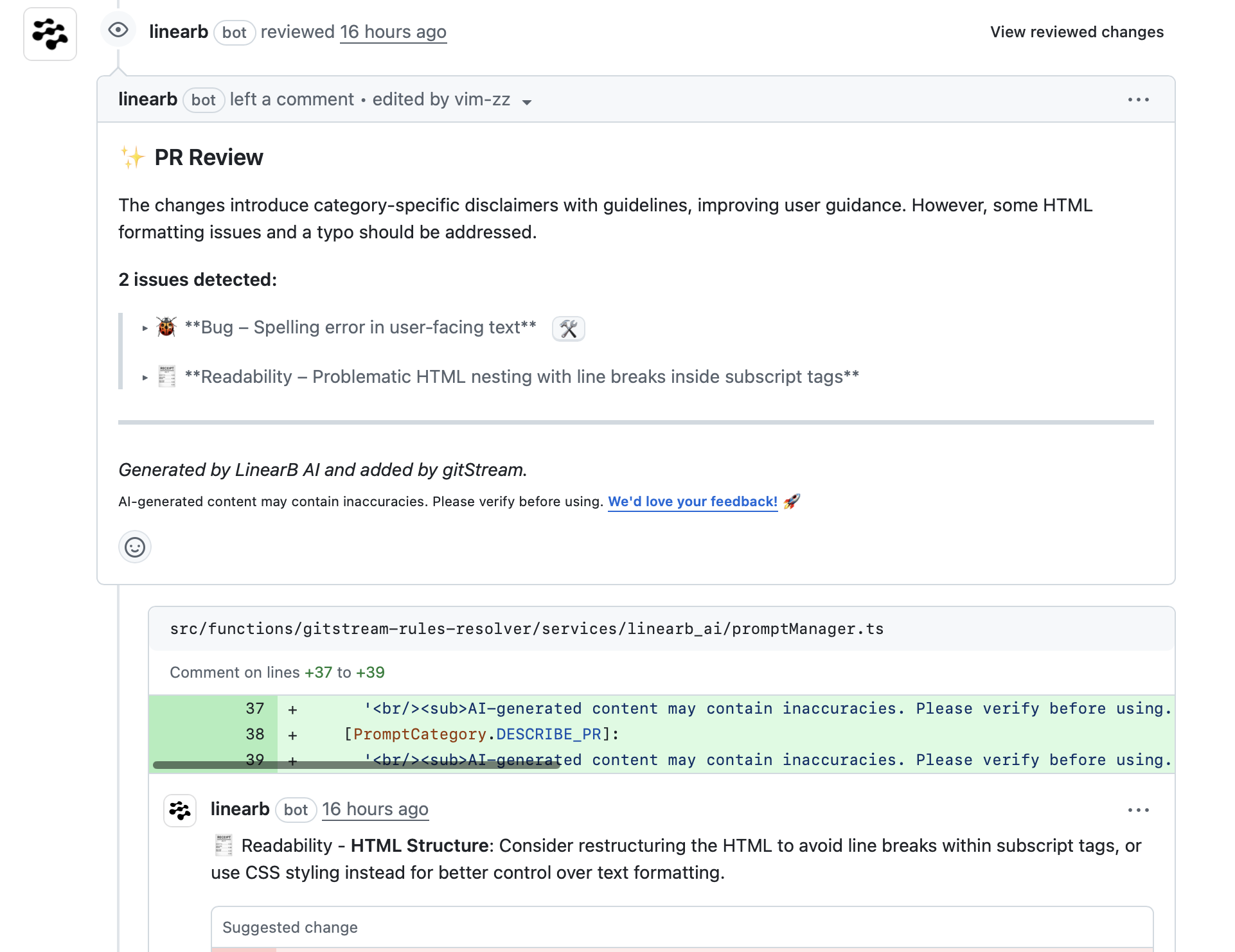
Reviews now visually flag issues that include suggested code corrections with a ⚒️ icon, helping you quickly distinguish between general comments and actionable fixes. This enhancement makes reviews easier to scan, helping you act on feedback faster and stay focused on what matters most in each PR.
When a suggested correction is available, you’ll see:
- A ⚒️ icon next to the issue title in the review summary
- A note in the comment body confirming a code suggestion is included
Measure AI adoption and impact across GitHub Copilot and Cursor
Now generally available to all users, track the real impact of GitHub Copilot and Cursor on your engineering productivity with out-of-the-box metrics dashboards in LinearB. Get a unified view of AI usage and performance across your organization:
- Measure adoption rates and daily active users for both tools
- Monitor AI-generated code suggestions and acceptance trends to uncover trust and productivity patterns
- Automatically detect and label PRs that involve AI tools to correlate activity with delivery metrics like cycle time, review time, and refactor rate
By centralizing your AI assistant metrics, you gain full context without toggling between platforms or sharing multiple API keys, making it easier to connect AI adoption directly to delivery outcomes. Learn more or read the docs on configuring GitHub Copilot and Cursor in LinearB.
Track Amazon Q adoption with the AI Insights Dashboard
You can now track AI usage metrics for Amazon Q, expanding support to 49 AI tools, including GitHub Copilot, Claude, Codex, Cursor, Gemini, and many more. Bring all your AI coding assistance usage metrics together in one place to monitor adoption, usage patterns, and productivity impact across your AI developer ecosystem.
How did we do?
Release Notes - July 2025
Release Notes - October 2025